AusCAT Architecture and Workflow#
Machine setup#
The AusCAT architecture can be summed up in the following diagram:
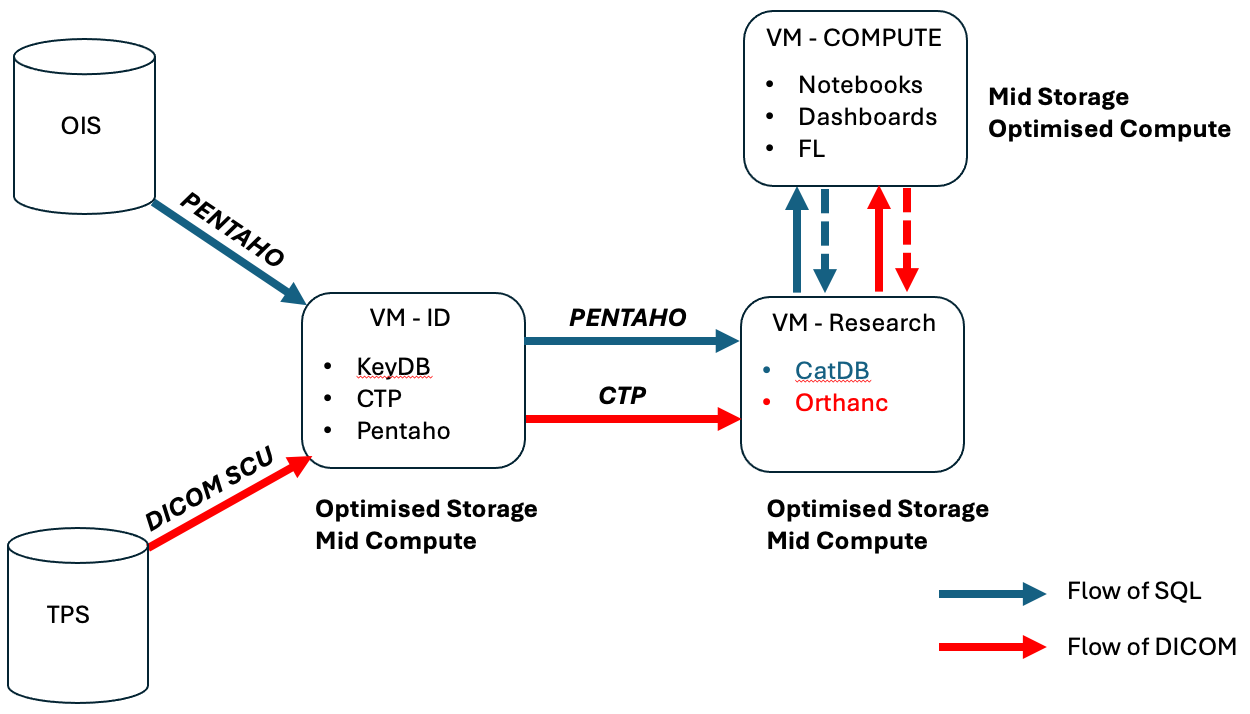
Essentially, your AusCAT node is made up of 2 main servers and/or virtual machines (VM’s). We highly recommend creating 2 physically separate servers and/or VM’s; one for handling and storing the patient identifiable information and another for handling the deidentified information. The reason being that the identifiable stores must not be accessed by anyone other than the specified data custodian at your particular centre and to limit any potential leakage of data to users who are not permitted to access it.
A third VM is recommended for end user usage, such as performing high compute, memory or GPU-dependent tasks. This ensures that the machines which hold the AusCAT databases are not affected by potential end-user misusage of the system and can help manange the costing of hardware easily, rather than placing all of your nodes infrastructure on the one node.
For more info on the specifications of these machines, please check out the AusCAT Architecture requirements guide here.
Workflow#
In summary and referring to the above diagram:
Patient Identifiable information flows from your clinic’s Oncology Information System (OIS) to the KeyDB Postgres database. The pipeline to run this is configured using the Pentaho tool (which is hosted on the same machine/VM as the KeyDB).
Once this info lands in the KeyDB and an anonymised ID is allocated to each patient, clinical information for each patient flows from your clinic’s OIC to the CatDB Postgres database, hosted on the second machine/VM. The pipeline to run this is configured using the Pentaho tool.
Once this info lands in the KeyDB and an anonymised ID is allocated to each patient, DICOM data can be transfered (via DICOM SCU) to the Clinical Trial Processor (CTP) tool (which is hosted on the same machine/VM as the KeyDB), which will deidentify the data using the KeyDB and place it in the Orthanc PACS Server (which is hosted on the ame machine/VM as the CatDB).